Y. Bando, M. Mimura, K. Itoyama, K. Yoshii, and T. Kawahara
Abstract: This paper presents a statistical method of single-channel speech enhancement that uses a variational autoencoder (VAE) as a prior distribution on clean speech. A standard approach to speech enhancement is to train a deep neural network (DNN) to take noisy speech as input and output clean speech. Although this supervised approach requires a very large amount of pair data for training, it is not robust against unknown environments. Another approach is to use non-negative matrix factorization (NMF) based on basis spectra trained on clean speech in advance and those adapted to noise on the fly. This semi-supervised approach, however, causes considerable signal distortion in enhanced speech due to the unrealistic assumption that speech spectrograms are linear combinations of the basis spectra. Replacing the poor linear generative model of clean speech in NMF with a VAE---a powerful nonlinear deep generative model---trained on clean speech, we formulate a unified probabilistic generative model of noisy speech. Given noisy speech as observed data, we can sample clean speech from its posterior distribution. The proposed method outperformed the conventional DNN-based method in unseen noisy environments.
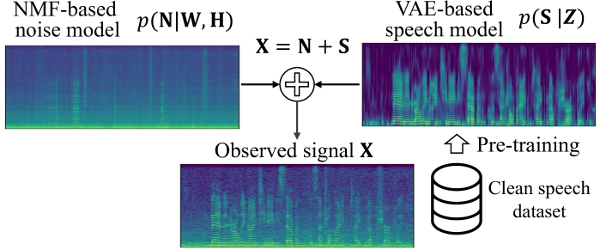
Fig. 1: Overview of our speech enhancement model.

Fig. 2: VAE representation of a speech spectrogram.
NOTE: the following results were not presented in the paper because we used simulated speech signals for SDR evaluation.
NOTE: DNN-IRM was trained using the noisy data recorded in the same environments as the following signals.
BUS (on a bus) condition
CAF (in a cafe) condition
PED (in a pedestrian area) condition
STR (on a streen junction) condition
NOTE: the noisy environments in this dataset are unknown to DNN-IRM.